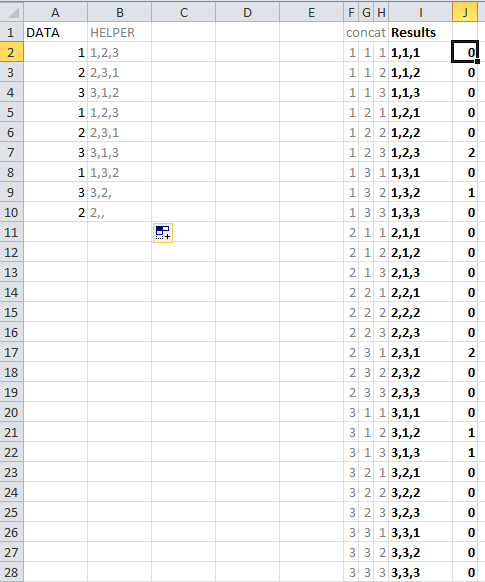
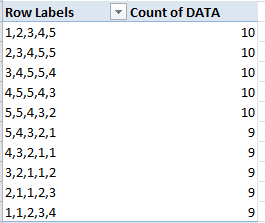
Это будет немного странно, у меня есть столбец из 750 строк заполняется целыми числами в диапазоне от 1-10. Я пытаюсь смотреть на эти данные как серия из 3 последовательностей строк и count количество вхождений для каждой последовательности, как это показано на следующем снимке экрана :
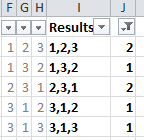
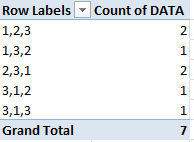
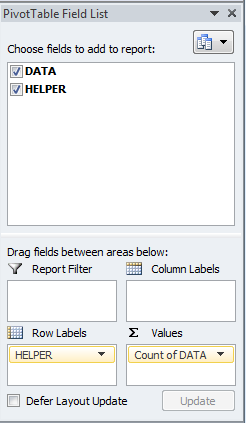
попытка найти и подсчитать 3 последовательности ячеек в excel. Столбец A является столбцом наблюдения с целыми числами от 1-3. Столбец I содержит список всех наблюдаются 3-значные последовательности, а столбец J-количество вхождений каждой из этих последовательностей наблюдается
столбец A является столбцом наблюдения с целочисленными значениями от 1-3 для данного примера. Столбец I содержит список всех наблюдаемых 3-значных последовательностей, а столбец J-количество вхождений каждой из этих последовательностей. Столбец I отображается как текстовое значение, но было бы лучше, чтобы один столбец превратился в 3 отдельных столбца; по одному для каждого значения в столбце. последовательность.
Я пытаюсь это как шаг для создания матрицы наблюдений Марковской цепи 2-го порядка. В предыдущей версии мне нужна была только матрица первого порядка, которая состояла из двух последовательностей значений. Я сделал это, создав 100 столбцов; один для каждой возможной комбинации. Затем в каждой строке каждого из этих столбцов я посмотрел ячейку на наблюдаемое значение (столбец A) для этой строки и строку над ней, и если последовательность соответствует последовательности для этого столбца, она выведет 1. В конце концов я суммировал каждый столбец и использовал эту информацию для создания счетчиков для матрицы наблюдений.
Я попытался записать это как массивную сетку всех возможных комбинаций, используемую в клеточных функциях, но быстро стало очевидно, что этот подход не сработает; 1000 столбцов из 750 строк представляют собой вычислительную проблему. Мне кажется, что может быть простой способ сделать это-vba, но я не уверен, возможно ли это вообще. Я начал преподавать себя, но есть еще многое, чего я не знаю. Это вообще возможно, или я зря трачу свое время?
Мне нужны два выхода: мне нужен список всех наблюдаемых последовательностей. Целые числа могут быть от 1-10, но не все 10, или может присутствовать вся комбинация из 10. Мне не нужны комбинации, которые не встречаются. Мне также нужно знать, сколько раз каждая последовательность наблюдается.
Я запускаю это на ПК с Windows 7 С помощью Microsoft Excel 1010. Я использую Microsoft Excel, поскольку это единственная математическая программа у меня есть, и это тот, который я наиболее комфортно.