Я пытаюсь найти способ захватить 4-5 строк текста с нескольких страниц одного и того же сайта, информация всегда находится в одном и том же месте на веб-странице. Как я могу получить эту информацию в текст или, предпочтительно, файл Excel?
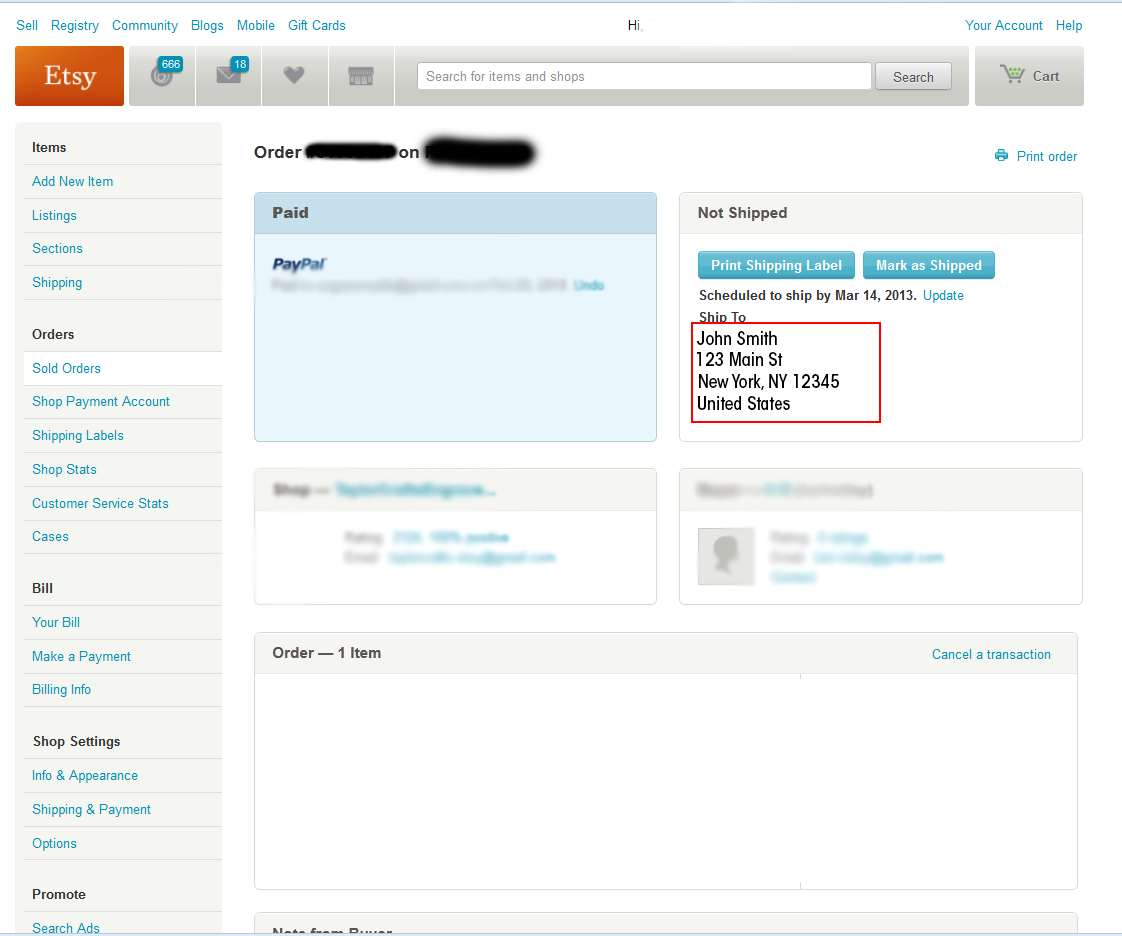
Я пытаюсь найти способ захватить 4-5 строк текста с нескольких страниц одного и того же сайта, информация всегда находится в одном и том же месте на веб-странице. Как я могу получить эту информацию в текст или, предпочтительно, файл Excel?

 3365
3365
традиционно вы загружаете HTML страницы и ищете некоторую константу, которая непосредственно предшествует вашим данным. к сожалению, Ваш вопрос не имеет универсального ответа, так как каждый сайт отличается. Я написал сценарии на python, Bash и даже C#, которые тянут страницу вниз, ищут ее тег, который я хочу, и извлекают его.
взгляните на источник страниц и найдите свой peice данных (firebug очень полезен для этого) и определите начальные и конечные разделители для содержимое, которое требуется извлечь.
вот некоторые скрипты, написанные для выскабливания XKCD.com http://forums.xkcd.com/viewtopic.php?f=11&t=63037

вы можете попробовать очистить страницу с помощью Javascript (в виде скрипта Greasemonkey / Userscript / расширения / букмарклета/...). Букмарклет означает, что вы должны вручную перейти на эту страницу и выполнить ее. Другие методы позволяют передавать данные непосредственно в базу данных (локальное хранилище при использовании привилегированного расширения или веб-сервера).
написание кода Javascript требует знаний в этой области, вы будете искать функции DOM, такие как document.getElementById,getElementsByClassName и querySelector или XPath. Поскольку Etsy уже использует jQuery, вы также можете использовать jQuery для получения данных.
в качестве альтернативы соскабливанию рассмотрите возможность использования API, если он доступен. Быстрый поиск показал следующие страницы, которые могут (или не могут) помочь вы:
это во многом зависит от того, в какой области находится ваш опыт, но в прошлом для такого рода операций я обычно использую PHP простой HTML DOM парсер. Он очень прост в использовании, а документация весьма информативна.
синтаксис запроса DOM очень похож на jQuery, если вы использовали его раньше.
вы можете использовать более подробном find('div[id=foo]'); и find('div[class=bar]'); но также можно использовать более компактный jQuery-подобный метод определения селекторов с find('#foo'); и find('.bar');.
Я лично использую Chrome Inspector для идентификации элементов, которые я хочу запросить, чтобы найти их идентификатор, класс, тег и т.д.
имейте в виду, что существует небольшая вероятность того, что вы можете столкнуться с ошибками памяти в зависимости от размера файла, который вы собираетесь загрузить в память, но если страница похожа на ту, что на скриншоте выше, у вас не должно быть проблем.
 |  |  |  |  |  |  |  |  |  |
Постоянная ссылка на данную страницу: [ Скопировать ссылку | Сгенерировать QR-код ]











