у меня есть файл Excel, который выглядит так:
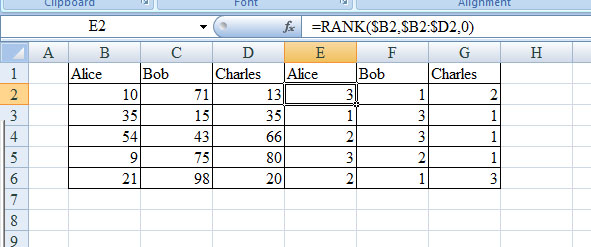
A B C D E F G H I J K L M N O
1 Alice Bob Charles
2 10 35 54 9 21 71 15 43 75 98 13 35 66 80 20
где каждая группа из 5 столбцов сообщает некоторые сведения относительно данного лица.
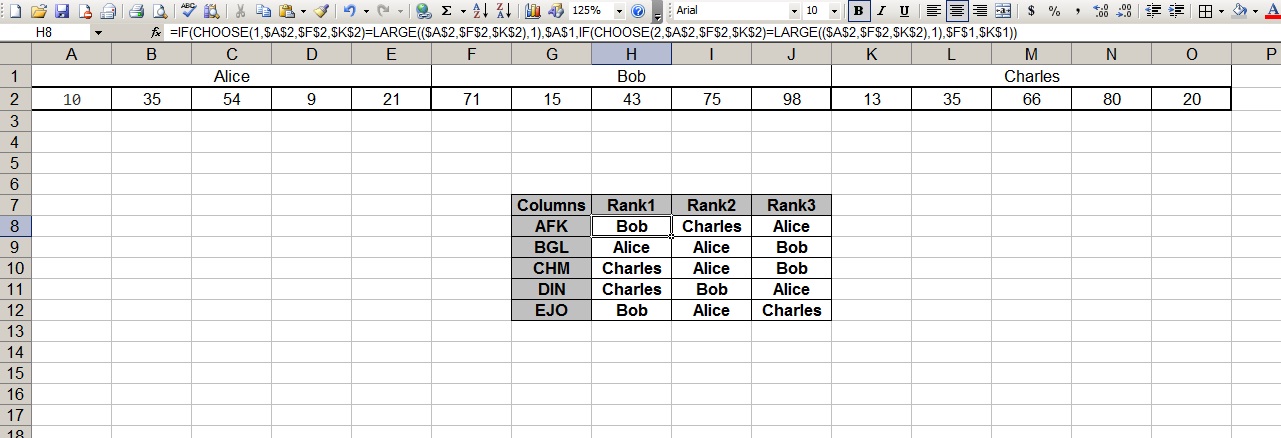
Я хочу построить пять рейтингов на основе значений в 5 столбцах каждой группы. Например, в рейтинге столбцы "а, Ж, К" должно быть "Боб, Чарльз, Алиса" (из-за стоимости в Боб-71, стоимость в Чарльз-13, а значение в Элис-10). Аналогичным образом, рейтинг "B, G, L" будет либо "Алиса, Чарльз, боб "или" Чарльз, Алиса, Боб " (потому что есть галстук: 35, 35, 15).
Я полагаю, что должен использовать сочетание INDEX / MATCH, (V)LOOKUP и LARGE, но действительно не знаю, с чего начать. Дальше всего я получил что-то вроде
LARGE((A2, F2, K2), 1)
LARGE((A2, F2, K2), 2)
LARGE((A2, F2, K2), 3)
Это (должно) вывести первое, второе и третье по величине значение для диапазона "A2, F2, K2", но я не знаю, как добраться до имени человека, связанного с этим значением оттуда. У меня есть некоторые проблемы обобщения примеры, которые я нашел с функциями INDEX / MATCH и lookup для этой нетипичной структуры данных (в группах из пяти столбцов).
EDIT: имена (Алиса, Боб, Чарльз) находятся на Объединенных ячейках.