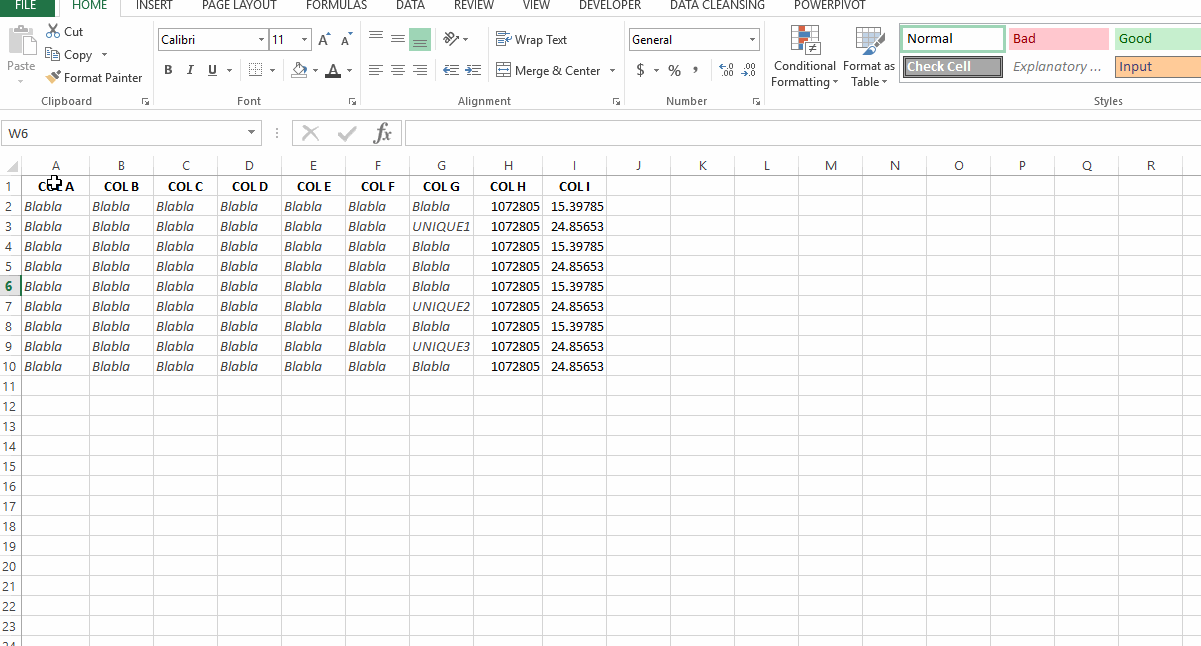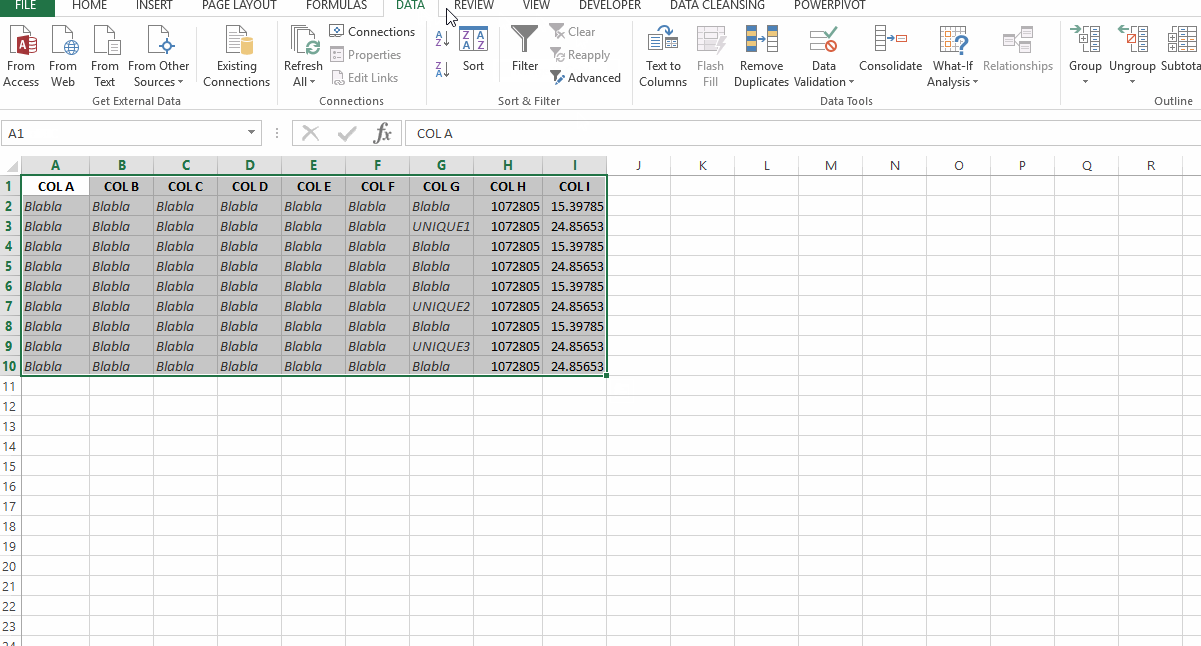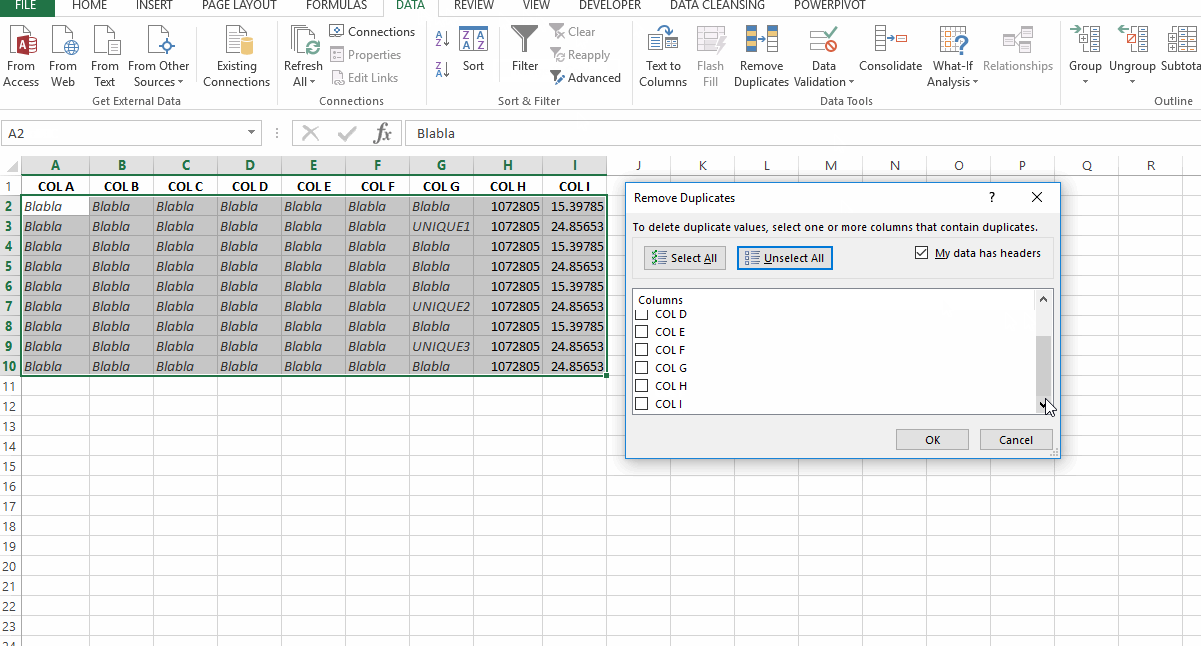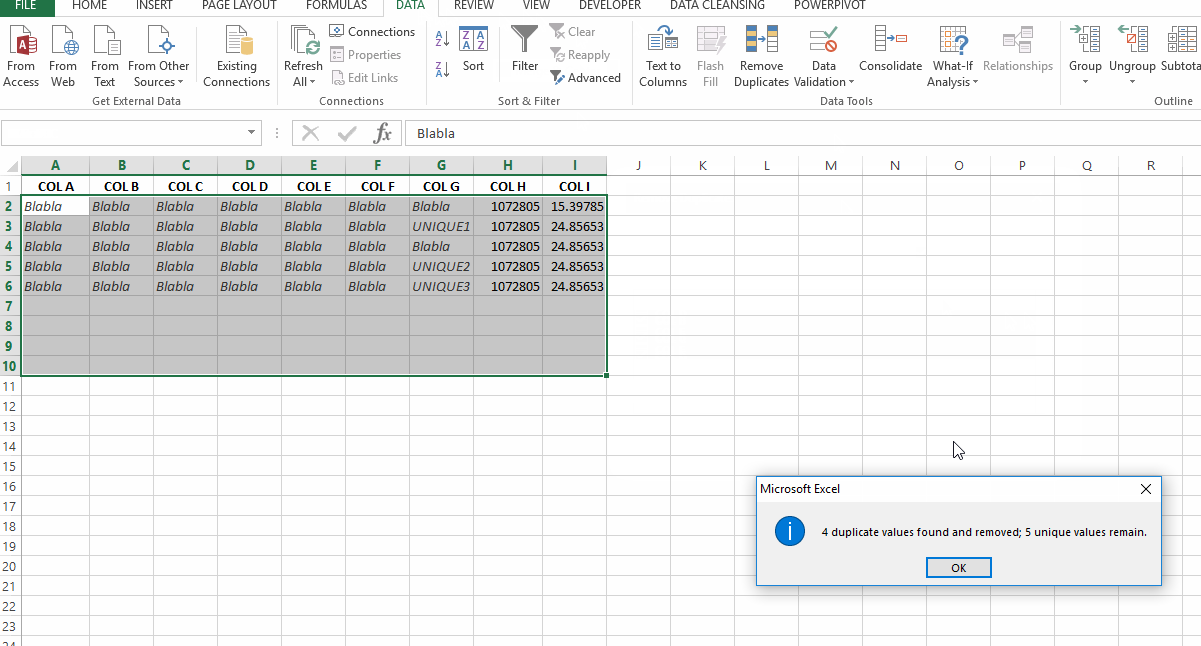
У меня есть набор данных, где я хочу удалить дубликаты в столбце H для каждого соответствующего уникального значения в столбце I. Например, на скриншоте в ссылке, если я просто удалю дубликат в столбце H, останется только 1 строка. Однако мне нужно сохранить оба уникальных значения в столбце I. обратите внимание, что я не могу просто удалить дубликаты в столбце I, потому что я не ищу уникальные значения в столбце I сам по себе, а скорее все применимые значения столбца I по отношению к каждому отдельному столбцу H значение. Как я могу это сделать?
пример скриншот