читая ваши комментарии и изменения к вопросу, есть несколько вещей, которые вы хотите сделать, которые на самом деле не рассматриваются в моем предыдущем ответе. Этот ответ будет иметь дело с этими элементами, и я включил пошаговое пошаговое руководство о том, как вы выполните весь процесс интерполяции.
Недостоверные Сведения
вы описываете процесс, который сгенерировал данные, как снятие показаний за интервал времени, а числа округляются. Тот уравнение так же хорошо, как и данные. В вашем фактическом анализе вы должны использовать самые точные доступные числа (возможно, вы просто сохраняли свой пример простым, показывая округленные времена).
Однако, данные, которые вы показываете, точно не соответствуют виду кривой, которую вы обычно видите для физического процесса. Теоретические кривые, как правило, гладкие, когда есть только одна движущая переменная и нет шума. Если вы используете очень точное оборудование и для того чтобы вызвать чтение на preset интервал и обеспечить точное измерение, вы можете принимать результаты как точные. Однако, если вы вручную приурочиваете чтение и вручную принимаете чтение, то X значения могут быть неточными, порой даже если показания, сами по себе, являются точными. Сдвиг персонажа X значения немного так или иначе введут виды небольших неровностей, которые вы видите на кривой ваших данных (если пример не является просто числами, которые вы составили для целей образец.)
если это так, вы можете воспользоваться регрессией для оценки наилучшего соответствия.
используя Y как X
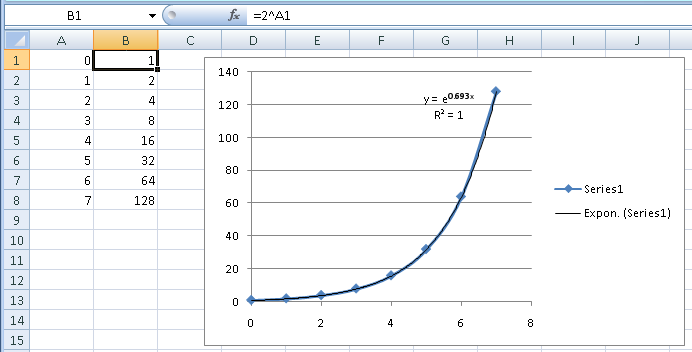
в вашей задаче вы хотите определить значения для Y (целочисленные значения от 1 до 37 в данном примере), и поиска соответствующего значения x. Это было достаточно легко сделать в вашей Y=2^X проблема, потому что это простое уравнение можно легко обратить к X=log(Y)/log(2), и вы можете сразу рассчитать любое значение вы хотите. Если уравнение не что-то простое, часто нет практического способа инвертировать его. "Злоупотребленный" регрессионный подход в моем предыдущем ответе дает вам уравнение высокого порядка, но это "однонаправленное", часто непрактичное решение для обратного уравнения.
самый простой подход-просто обратить X и Y С самого начала. Это дает уравнение можно использовать с целочисленными значениями введут (анализ дает coeficients уравнения, как описано в предыдущем ответ.)
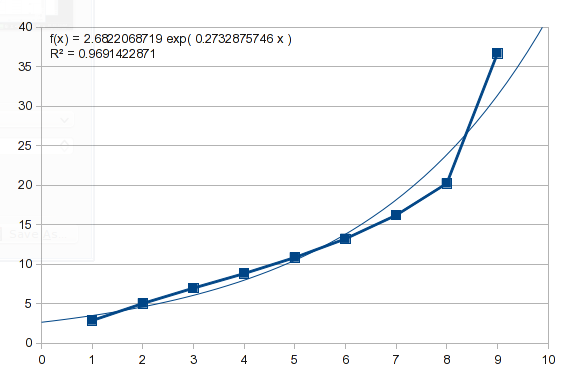
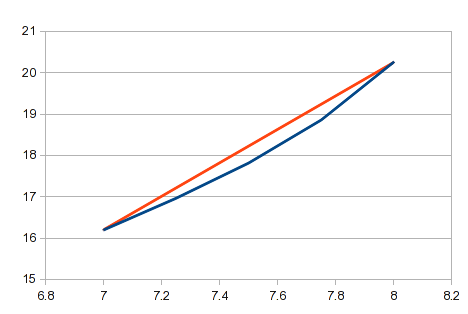
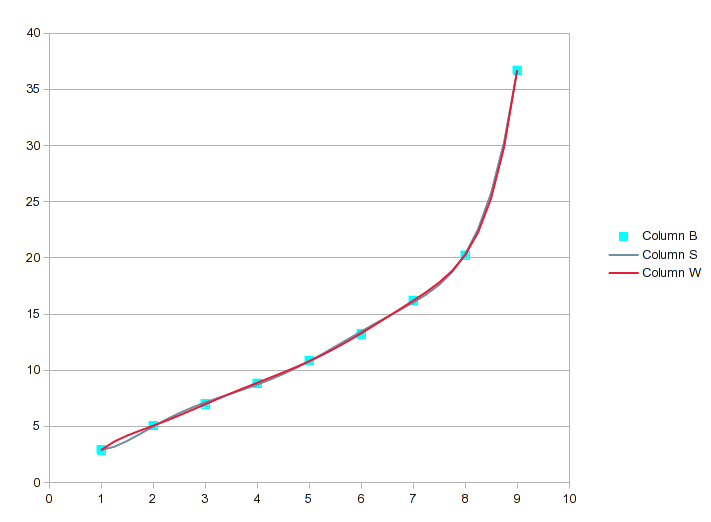
это никогда не повредит, чтобы увидеть, если простая кривая будет работать. Вот обратные данные, и вы можете видеть, что нет полезной подгонки:
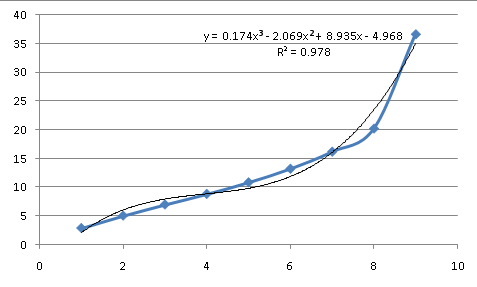
Итак, попробуйте полиномиальную подгонку. Однако это случай, как я описал в предыдущем ответе. Значения от 1 до 8 подходят хорошо, но 9 дает ему несварение. Многочлен 3-го порядка дает вам bump:
это становится все более "интересным" по мере увеличения порядка уравнения. По 7-м порядка, вы получите это:
он проходит почти точно через каждую точку, но кривая между 8 и 9 не полезно. Одним из решений было бы обойтись линейной интерполяцией между 8 и 9. В этом случае, однако, вы можете получить лучшие значения включение сплайнов для верхнего конца. Опция сплайны обеспечивает хорошую посадку и кривую, которая имеет больше смысла между 8 и 9:
к сожалению, сплайновые уравнения немного запутаны и уравнения не представлены. Тем не менее, вы можете сделать линейную интерполяцию на промежуточных значениях, предоставляемых анализом, которая должна получить Вас очень близко к числам, которые соответствуют разумным кривая.
экстраполяция и интерполяция
в этом примере, Ваш первый Y значение 2.9. Вы хотите создать значения для 1 и 2, которые находятся вне диапазона данных. Это требует экстраполяции, а не интерполяции, что является совершенно иным требованием.
если уравнение известно, как ваш Y=2^X пример, вы можете рассчитать любое значение, которое вы хотите.
если известно, что процесс генерации данных следует простой кривой, и вы уверены в подгонке, вы можете проецировать значения за пределы диапазона данных и даже получить значимый доверительный интервал для диапазона, в котором могут быть значения (на основе того, сколько вариаций между данными и кривой внутри диапазона данных).
если вы принудительно подгоняете уравнение высокого порядка к данным, проекции вне диапазона данных обычно бессмысленны.
если вы используете сплайны, нет оснований для проецирования за пределы диапазона данных.
какие бы проекции вы ни делали за пределами диапазона ваших данных, они хороши только как уравнение, которое вы используете, и если вы не используете точное уравнение, чем дальше вы получаете от своих данных, тем более неточным оно будет.
глядя на кривую журнала на первом графике, вы можете видеть, что она будет проецировать совсем другое значение чем вы и ожидали.
для полиномиальных уравнений коэффициент нулевой мощности является константой, и это значение, которое будет получено для X стоимостью 0. Это простой способ посмотреть, куда пойдет кривая в этом направлении.
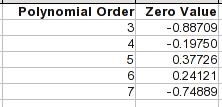
обратите внимание, что в 4-м или 5-м порядке точки с 1 по 8 довольно точны. Но как только вы выходите за пределы диапазона, уравнения могут вести себя очень иначе.
экстраполяция с использованием ограниченных данных
один из способов улучшить ситуацию-подогнать только точки На этом конце и включить столько последовательных точек, сколько следует за формой кривой на этом конце. Точка 9-это явно. Перед этим на кривой есть несколько перегибов, один из которых находится вокруг точки 5 или 6, поэтому точки выше этого следуют другой кривой. Используя только точки от 1 до 5, вы приближаетесь к идеальной подгонке с полиномом 3-го порядка. Это уравнение будет нулевой точки 0.12095 (сравните таблицу выше), а для X стоимостью 1,0.3493.
что произойдет, если просто подогнать прямую к первым пяти точкам:
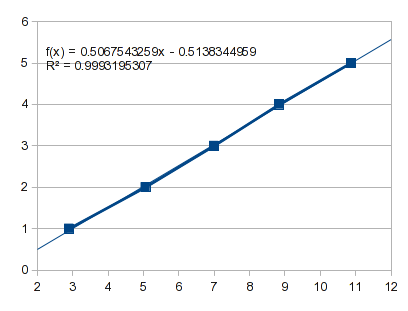
что проектов с нулевой точки -0.5138 и X на 1,-0.0071.
этот диапазон возможных результатов указывает на уровень неопределенности за пределами диапазона ваших данные. Нет правильного ответа. И это было на" хорошем " конце твоей кривой. The Y значение X на 9 is 36.7. Ты хочешь пойти в 37. Сплайны предполагают, что кривая асимптотична при 9. Проецирование прямой линии в необработанных данных приведет к значению чуть больше, чем 9 (то же самое с полиномом 4-го порядка). Полином 3-го порядка предлагает значение меньше 9 (как сделать 5 и 6 заказов). Многочлен 7-го порядка предлагает значение существенно выше 9. Таким образом, все, что находится за пределами диапазона данных, является предположением или чем-то другим.
собираем все вместе
Итак, давайте шаг через то, что фактическое решение будет выглядеть. Мы предположим, что вы уже пытались найти точное уравнение и протестировали общие кривые с помощью линии тренда. Следующим шагом будет попробовать регрессию, потому что это дает вам формулу для кривой, и вы можете подключить целочисленные значения.
I нет готового доступа к Excel 2013 или инструментарию анализа. Для иллюстрации я буду использовать LibreOffice Calc. Он не идентичен, но достаточно близок, чтобы вы могли следить за ним в Excel. В LO Calc это фактически бесплатное расширение, которое необходимо загрузить. Я использую CorelPolyGUI, которую можно скачать здесь. Насколько я помню, инструментарий анализа не включал сплайны. Если это все еще так, и вы хотите сделать это в Excel, я наткнулся это бесплатное дополнение (который я не проверял). Альтернативой будет использование Lo Calc, который будет работать в Windows и является бесплатным.
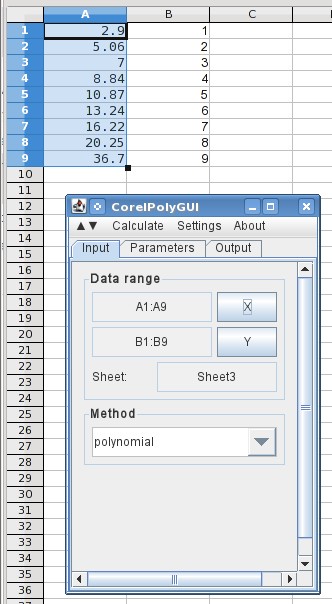
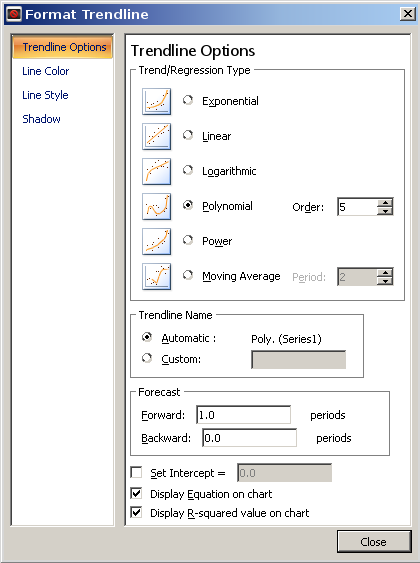
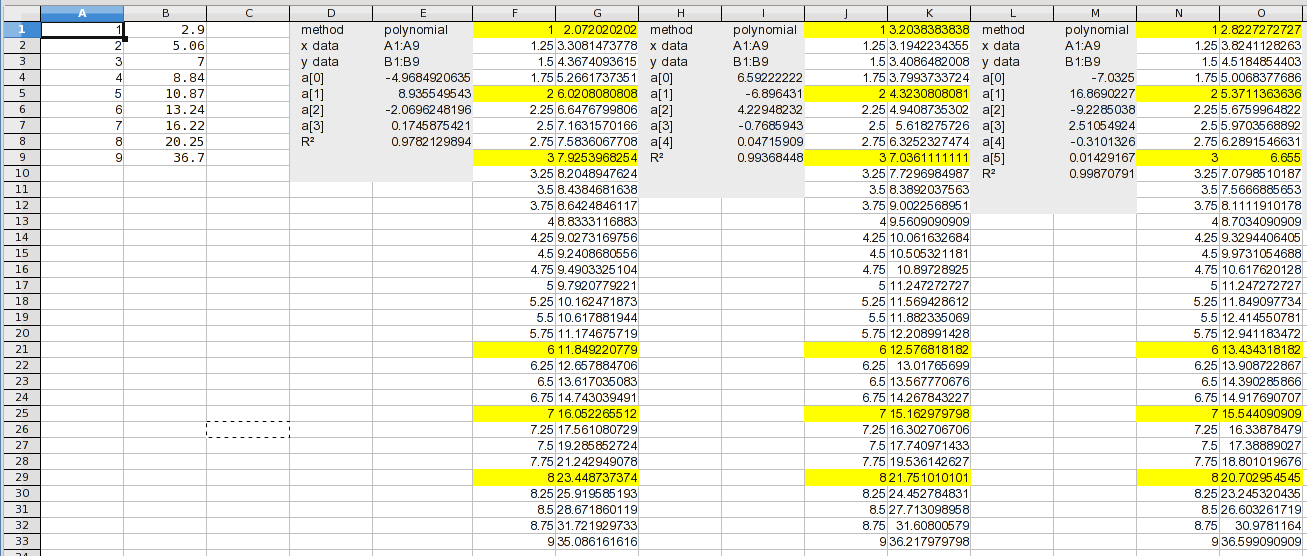
здесь я ввел значения X и Y (реверсированные) в Столбцах A и B и открыл диалоговое окно анализа. Выделение значений X и нажатие кнопки X загружает диапазоны данных, и я выбрал полином.
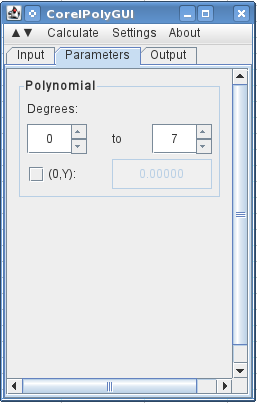
на следующей вкладке я указываю, что хочу использовать 0 to 7 Градусы (многочлен 7-го порядка со всеми порядками).
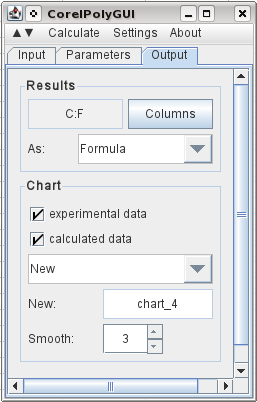
чтобы указать вывод, я выбираю C1 и нажимаю столбцы, и он регистрирует столбцы, необходимые для вывода. Я выбираю, что я хочу, чтобы он выводил исходные данные, вычисленные результаты, и я выбрал добавьте три промежуточные точки между каждой исходной точкой данных. И я говорю, что хочу график результатов на новом графике. Затем перейдите в меню calculate и нажмите calculate.
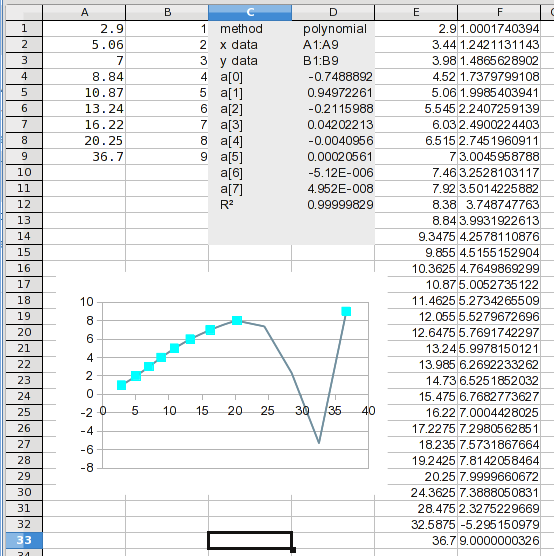
и вот оно. Если вы посмотрите на вычисленные значения, вы можете заметить проблему. Это станет очевидным на следующем этапе.
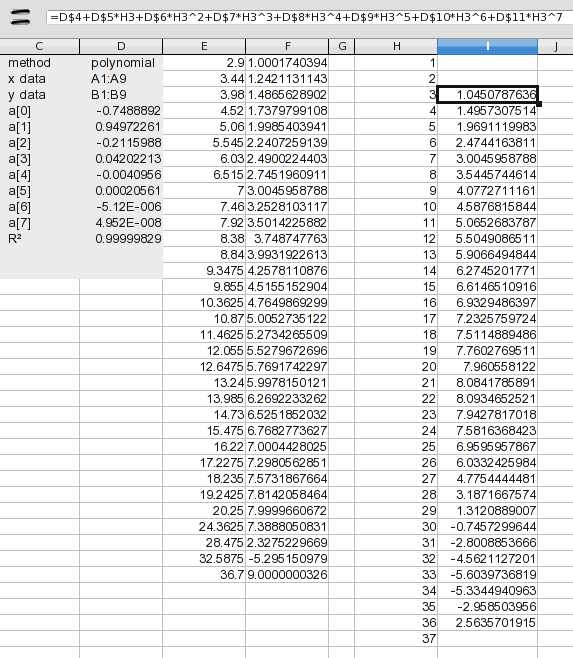
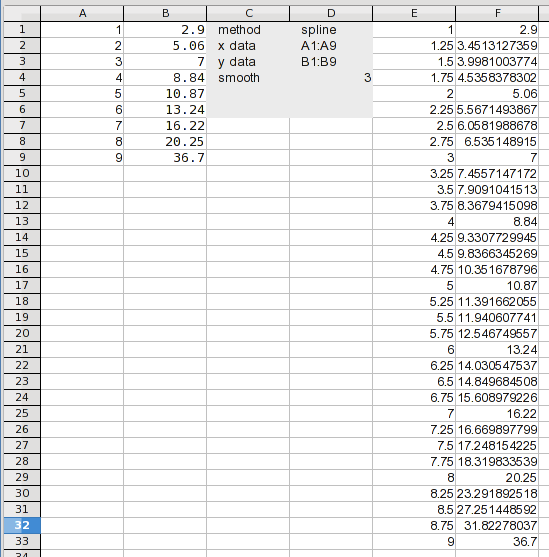
вот, я добавил 1 через 37 значения. На данный момент мы хотим иметь дело только с интерполяцией, поэтому я добавил формулу для вычисления только значений 3 через 36. Формула просто расширяет коэффициенты, перечисленные в результатах (значения a (n)). Формула в I2:
=D+D*H3+D*H3^2+D*H3^3+D*H3^4+D*H3^5+D*H3^6+D*H3^7
это просто каждый коэффициент, умноженный на соответствующую мощность значения X. Перетащите это вниз, и у вас есть результаты. Ну не совсем; Вы должны смотреть на него, чтобы увидеть, если он проходит здравомыслие испытание. Мы знали, что между 8 и 9, но это оказывается половина значений, которые вы хотите. Мы могли бы использовать значения из 3 через 20, но нет смысла объединять так много значений из другого метода. Так что давайте просто использовать сплайны для всего этого.
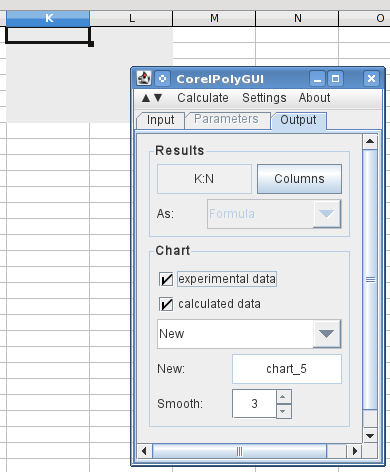
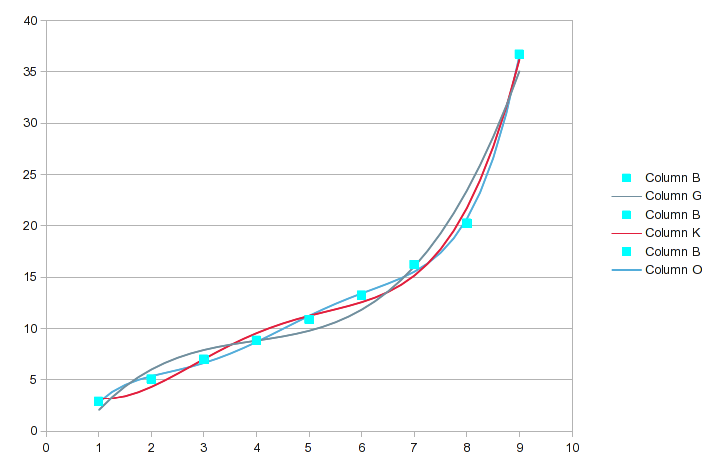
снова откройте диалоговое окно анализ и измените метод на "сплайны" на вкладке ввод (здесь не показано). Дайте ему новое выведите наружу ряд и скажите, что он высчитал. Это все, что для этого нужно.
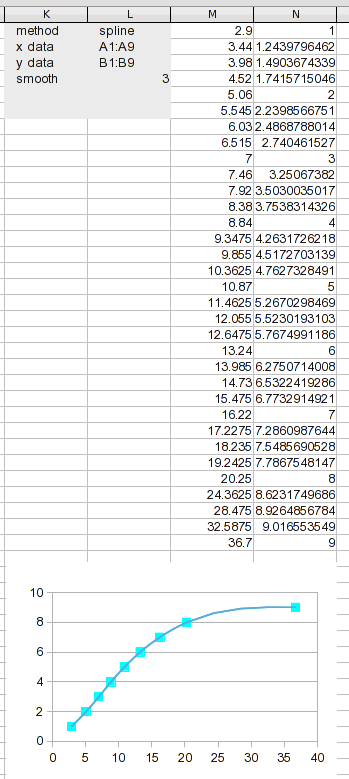
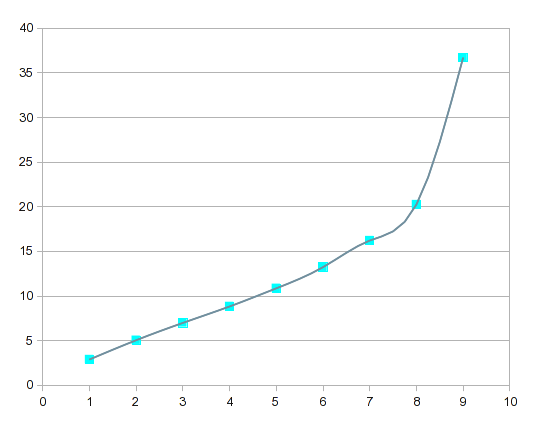
у нас есть новые результаты в работе. Разделение диапазона данных на это множество сегментов делает каждый сегмент коротким, поэтому линейная интерполяция должна быть довольно хорошей (лучше, чем использовать ее на исходных данных).
процесс подгонки кривой или интерполяции включает в себя создание точек данных; используя свое собственное суждение о том, что кривая "должна" (или не должна) выглядеть (регрессия предполагает, что даже исходные данные неточны).
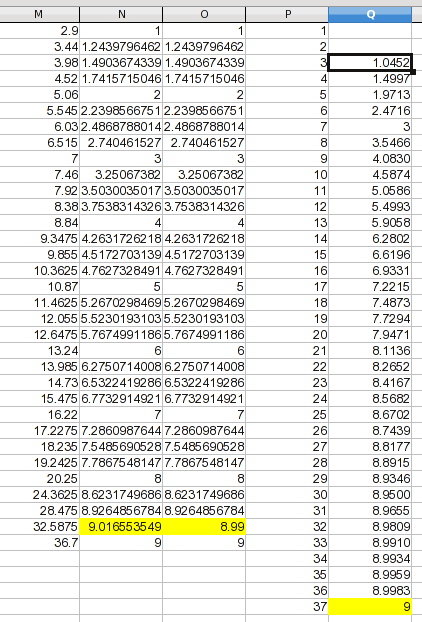
проверка правильности этих данных показывает, что даже сплайны создают соединительную кривую с выпуклостью; одно значение немного превышает 9, который скорее артефакт, нежели отражение процесса вы были измерения. В этом случае кривая асимптотика при 9 более вероятно, поэтому я произвольно назначил высокую точку a значение, что волос меньше!--24 -- > глядя на него. Предположение не в том, что моя ценность точна, только в том, что это улучшение. Для этой иллюстрации я создал новый столбец со значениями, которые будут использоваться.
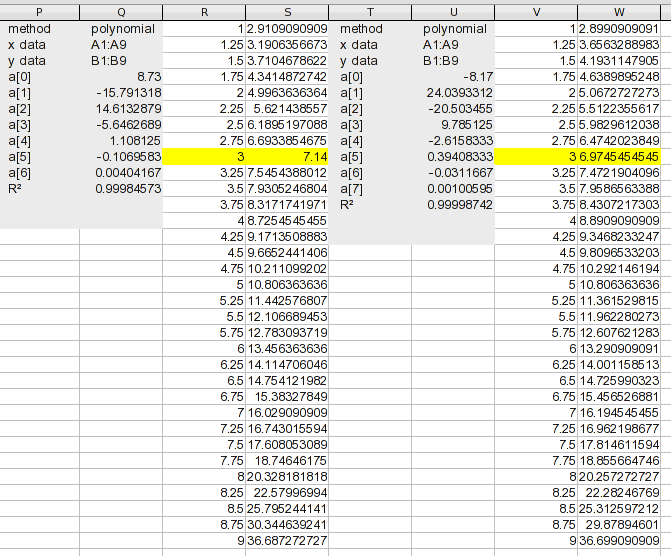
я добавил столбец с вашими номерами 1 через 37. Из предыдущего обсуждения у нас нет надежной основы для проектирования значений для 1 и 2, поэтому я оставил их пустыми. Для 37, я пошел с асимптотическим предположением и сделал это 9. Значения для 3 через 36 найдены линейной интерполяцией (и это формула, которую вы могли бы адаптировать к другим данным). Формула в Q3:
=TREND(OFFSET($M,MATCH(P3,M:M)-1,2,2),OFFSET($M,MATCH(P3,M:M)-1,0,2),P3)
функция TREND просто интерполирует, когда диапазон равен двум точкам. Синтаксис команды:
TREND(Y_range, X_range, X_value)
функция смещения используется для каждого диапазона. В каждом случае функция MATCH используется для поиска первой строки диапазона, содержащего целевое значение. The -1 значения, потому что это смещения, а не местоположения; совпадение в первой строке является смещением 0 из исходной строки. И обратите внимание, что Y столбец смещен на 2, в данном случае, потому что я добавил дополнительный столбец для ручной настройки значения. Параметры смещения выбирают столбец, содержащий значения Y или X, и выбирают высоту диапазона 2, которая дает вам значения ниже и выше цели.
в результат:
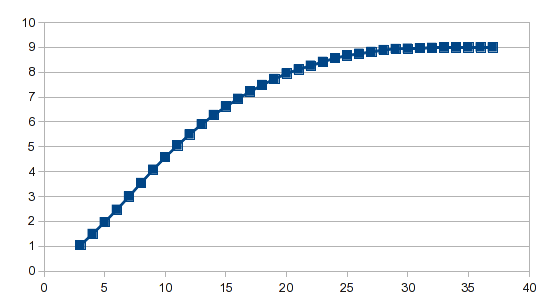
мастер анализа делает тяжелую работу, и независимо от того, используете ли вы полиномиальную регрессию или сплайны, для генерации результата требуется всего одна формула.