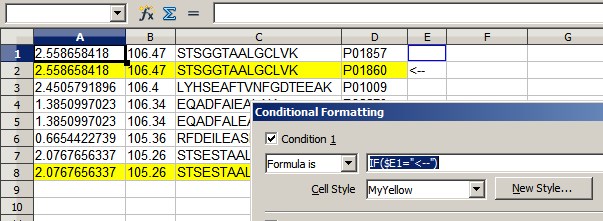
у меня большая таблица (20-30 cols, 10-15K строк). Что мне нужно сделать, так это найти количество строк, которые совпадают одинаково в одном (или двух) конкретном поле(полях), но не в другом конкретном поле (остальные поля не имеют значения). Кроме того, я хотел бы использовать условное форматирование для выделения таких строк. Можно ли обойтись без скриптов?
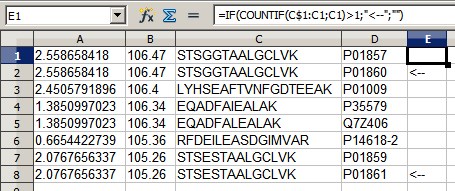
пример таблицы с 10 строками и 4 cols:
2.558658418 106.47 STSGGTAALGCLVK P01857
2.558658418 106.47 STSGGTAALGCLVK P01860 <--
2.4505791896 106.4 LYHSEAFTVNFGDTEEAK P01009
1.3850997023 106.34 EQADFAIEALAK P35579
1.3850997023 106.34 EQADFALEALAK Q7Z406
0.6654422739 105.36 RFDEILEASDGIMVAR P14618-2
2.0767656337 105.26 STSESTAALGCLVK P01859
2.0767656337 105.26 STSESTAALGCLVK P01859
2.0767656337 105.26 STSESTAALGCLVK P01861 <--
2.0767656337 105.26 STSESTAALGCLVK P01861
что я бы в таком случае получите счетчик равным 8 и, если возможно, чтобы строки, которые я отметил стрелками (ради примера), были выделены. Обратите внимание, что если третье и четвертое поля идентичны (т. е. если разница между строками находится в другом месте таблицы), то это не ряд интересов.
Я обычно не работаю с Excel / OOCalc, поэтому я чувствую себя немного неуместным, работая с такими таблицами. Я наткнулся на некоторые инструкции / форумы одним из которых содержит предложение использования COUNTIFS (например,=COUNTIFS(C2:C114, "YES", F2:F114, "> 0")) или эквивалент OOCalc с SUMPRODUCT (например,=SUMPRODUCT(C2:C114="YES" ; F2:F114>0)
проблема с этим подходом заключается в том, что он сопоставляет содержимое ячейки на заданное значение типа "YES". В моем случае я хотел бы сравнить содержимое ячейки с содержимым ячейки непосредственно выше / ниже. Можно ли настроить приведенные выше формулы в соответствии с моим случаем?