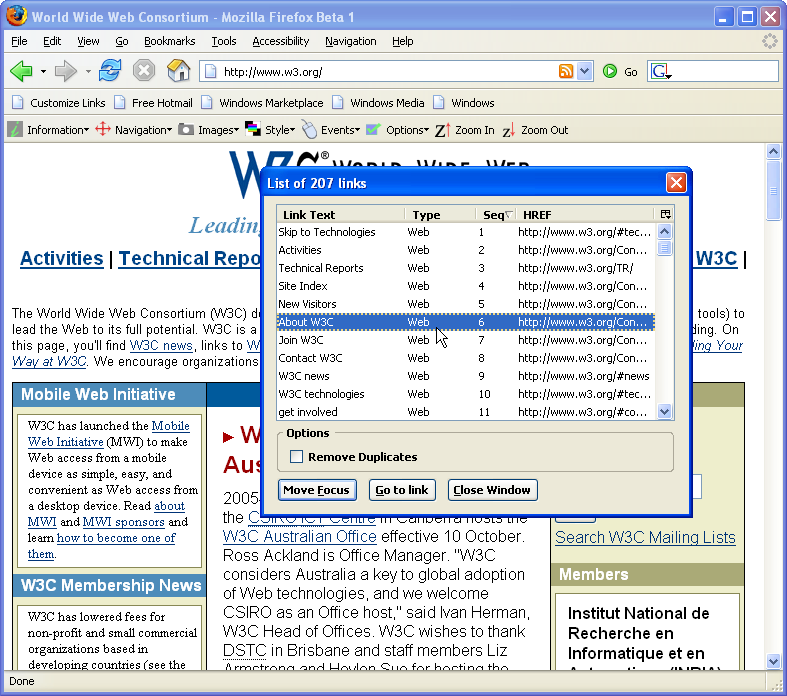
скачать Текст Гусеничном Ходу (это бесплатно) и установить его. Запустите его после завершения установки. В поле Имя файла/фильтр введите"*".htm *.формат HTML.* php " или какими бы ни были расширения HTML-файлов, которые вы анализируете. В окне Пуск перейдите в каталог, где находятся файлы. По умолчанию он также сканирует подкаталоги, если вы не хотите эту функциональность, то вы можете нажать на опции, а затем снимите флажок "сканировать подпапки". В поле Найти введите in:
<a.*?href\s*=\s*["'](.*?)['"].*?>(.*?)</a>
убедитесь, что рядом с надписью "использовать регулярные выражения" стоит галочка. Затем нажмите кнопку Найти. Он покажет вам все ссылки, сгруппированные по файлам, в которых они находятся. Вы также можете нажать на извлечение, которое появится окно со всеми ссылками из всех файлов. Поскольку вы заявили, что хотите ссылки, я решил, что вы хотите весь
<a href="something.php">Something</a>
, так что вы можете увидеть, где ссылка и что описание. Если вы хотите только ссылку без тегов, измените регулярное выражение на
href=[\"\'](http:\/\/|\.\/|\/)?\w+(\.\w+)*(\/\w+(\.\w+)?)*(\/|\?\w*=\w*(&\w*=\w*)*)?[\"\']
что вернет
href="something.php"
Дайте мне знать, если это ответ на ваш вопрос. TextCrawler является удивительным приложением, и так как это бесплатно его стоит попробовать.

 2873
2873